
Oak Ridge National Laboratory’s Frontier supercomputer. [Credit: ORNL]
Access to Frontier “changed our company overnight,” Narain said. With power exceeding a quintillion calculations per second – that’s a one followed by 18 zeros – Frontier can accomplish in a heartbeat what would take the entire global population four years of non-stop work, as a promotional video for the computer notes.
Supercomputer vs. superbug
The impact of this collaboration was thrown into sharp relief during the COVID-19 pandemic of 2020. BPGbio, then known as Berg Health, reached out to Oak Ridge National Laboratory, hoping to tap into the power of the Frontier supercomputer. The company forged an alliance with Jeremy Smith, Ph.D., director of the UT/ORNL Center for Molecular Biophysics, and fed millions of patient records, along with virus data, into Frontier’s system. “They came back to us a couple of days later. I was astonished that this was even possible,” says Niven R. Narain, Ph.D., CEO of BPGbio. The results weren’t just fast; they shed light on a key question that had stumped scientists early on in the course of the pandemic: why some ethnicities appeared to be especially hard hit by SARS-CoV-2 infection.
The supercomputer’s analysis pointed to a potential factor: “African Americans and those of Middle Eastern origin [tended to have] a higher copy number of the ACE2 receptor in the kidneys, the lungs, the brain, and the gut,” Narain explains. While other factors, including socioeconomic disparities and underlying health conditions, also contribute to COVID-19 severity, more ACE2 receptors means more virus replication, leading to worse outcomes. “This is the machinery where this virus is interacting,” Narain said. “If one person has 10 copies and another has 100, the second is going to make a lot more virus, and that’s what was happening.” This discovery was published in the peer-reviewed Journal of Racial and Ethnic Health Disparities.
Beyond COVID: Tackling unsolved medical challenges
BPGbio’s drug and diagnostics discovery strategy is rooted in a compute-intensive Bayesian approach, integrated into its proprietary NAi Interrogative Biology platform. This platform exploits supercomputing to analyze massive patient datasets, including data from the company’s clinically annotated biobank containing over 100,000 samples. This enables hypothesis-free target nomination, discovery, and molecule design. Key elements include purpose-built AI software and the ORNL Frontier supercomputer. “Essentially, we’re embedding our algorithms and our AI capability within the [Frontier] computer,

Niven R. Narain, Ph.D.
The NAi Interrogative Biology platform goes beyond sheer computational power and stands out through its comprehensive approach. By analyzing multi-omics data (genomic, proteomic, metabolomic, etc.), the platform reveals a deeper understanding of disease mechanisms. Think of it like this: ZIP codes provide basic location information, but to truly understand an area, you need to analyze what’s within each one — its demographics, businesses, resources, etc. “Imagine if you compared every ZIP code in this country…one by one, and one by two, and one by three…that’s what the Bayesian system is doing,” Narain said.
In the context of multi-omics data analysis, the ZIP code metaphor underscores the platform’s capability to assess complex interactions between genes, proteins, metabolites and so forth to uncover complex biological networks and pathways involved in disease mechanisms. “It’s trillions of data points per patient,” Narain said. This data-intensive approach has already delivered over 100 drug and diagnostic targets/candidates, including BPM31510 IV, currently in Phase 2b and Phase 2a trials for glioblastoma multiforme and pancreatic cancer, respectively.
Accelerating research with powerful computation + experimentation
With Frontier, BPGbio’s drug discovery approach can exploit immense computational resources. Frontier enables rapid iteration, saving resources. “It allows us to fail a lot faster. So instead of spending hundreds of thousands of dollars on something that may not work, we can kill that in days to a week,” Narain explains. Beyond efficiency, this power unlocks projects previously unimaginable in scale and complexity. “We’re able to use the compute power to do projects that we otherwise could not do in scale, vision, and certainly in time.”
“What it meant for us is this was transformational for any of our enabling platforms and technologies. But it also importantly allowed us to think a lot bigger and think with a lot more confidence,” Narain emphasizes. “[They] can screen a core of billions of molecules in a matter of days.”
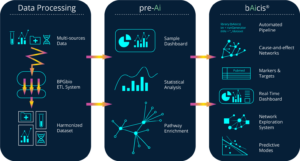
BPGbio’s NAi Interrogative Biology Platform integrates data harmonization, AI-driven analysis, and high-performance computing to accelerate drug and diagnostics discovery. [BPGbio]
Forging new drug discovery ground
Despite advances in computational capabilities, scientists’ understanding of biology remains limited. “We don’t even know what we don’t know,” Narain said. But in the coming years, as computational tools become more sophisticated and we integrate vast biological datasets, we’ll uncover hidden patterns and relationships. This could reveal novel disease mechanisms, but translating those insights into new therapies will take a concerted effort from biologists, chemists, and clinical researchers. “It’s not only enough to get the data from the computer, you have to now know how to put that into a relevant disease model to test it and validate that that change actually means something,” he said. And then researchers need to test this in a patient population. They must formulate their null hypothesis, investigate ways to disrupt the target pathway, and determine if these manipulations increase or decrease disease progression. This rigorous process, where computational insights meet experimental validation, will push the field closer to breakthroughs. “I think we are etching on that frontier.”
Filed Under: Data science, Drug Discovery and Development, machine learning and AI, Oncology


