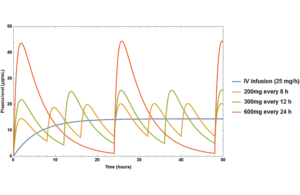
Simulated drug plasma concentration over time curves following IV infusion and multiple oral doses. Image courtesy of Wikimedia Commons.
Historically, healthcare organizations have followed the lead of published research on the efficacy of pharmacokinetic (PK) models to support point-of-care precision dosing. When a respected journal publishes a robust, peer-validated PK model analysis, clinicians often heed the results and accept that model as their organization’s default for the drug in question. However, new research shows that PK models require frequent reassessment and reevaluation — and that their utility may vary significantly depending on the site. In short, large-scale findings might not apply to an individual hospital’s patient population.
Let’s look at vancomycin, a drug commonly associated with model-informed precision dosing (MIPD). In 2020, a new consensus guideline for the therapeutic monitoring of vancomycin for serious methicillin-resistant Staphylococcus aureus infections was issued by the American Society of Health-System Pharmacists, the Infectious Diseases Society of America, the Pediatric Infectious Diseases Society, and the Society of Infectious Diseases Pharmacists.
Why Bayesian analysis?
In place of historic trough-based dosing, the guidelines now recommend dosing to optimize the area under the curve to the minimum inhibitory concentration (AUC/MIC) ratio, targeting 400–600 mg-hr./L. Notably, the new guidelines state that the preferred method is to use a Bayesian software program to calculate dosages rather than manual calculations. Given the inherent variability of every measured level in the body — as well as sampling and lab variability — taking a patient’s measured level at face value tends to produce less precise results than Bayesian forecasting, which accommodates this variability within its calculations.
Bayesian forecasting in response to measured levels is a subset of MIPD, which can apply to all dosing phases. In initial dosing, MIPD can help interpret a patient’s parameters — such as their serum creatinine levels, gender and height/weight — through a PK model to produce patient-specific drug exposure predictions. Once the patient’s medication levels have been measured, the clinician can abandon this a priori approach (based on theory only) in favor of an a posteriori Bayesian approach, which incorporates observational data.
MAP-Bayesian analysis uses the maximum a posteriori estimate, or the most probable model parameters, to interpret the patient’s levels in the context of the PK model. This analysis produces the most accurate patient-specific drug exposure predictions available —but the accuracy of those predictions still depends upon the PK model. As precision dosing technology gains momentum, clinicians are becoming more interested in how to assess the efficacy of one PK model versus another. Which is the best model to use for a given patient population?
The rise of democratized research
Hospitals need the ability to find their own ideal PK model — or models, depending on their clinical preferences — on a site-specific basis. In the new vision of democratized research, healthcare organizations can use aggregated, de-identified patient data to better understand and evaluate the efficacy of various PK models on their own.
In this vision, every hospital, from the largest healthcare network to the smallest rural clinic, can conduct research on their own patients. By using a clinical decision support tool for prospective dosing, hospitals can use MIPD technology — which relies on validated PK models — to make the best possible dosing decisions for a specific patient. Each dosing decision is collected in an immense, ever-growing database of clinical data points.
However, it’s the second component of a precision dosing ecosystem that supports creating a democratized research network. When clinicians have access to their aggregated, de-identified patient data, they can then examine their data to see how they’re performing and uncover unexpected variations. In addition, real-time analytics allows organizations to detect unanswered questions that warrant further analysis.
These local findings, or data signals, are subsequently shared to the larger network of hospitals, which can then locally reassess the results to discover if they hold true for their unique patient population. If the data signal is strong enough, it can then be escalated to a centralized data science team, with access to de-identified patient data from hundreds of institutions, for large-scale analysis.
The centralized team can formulate a scientific question to be asked, define an appropriate dataset, and simulate PK model performance by determining what a model would have predicted for specific patients and comparing those figures to the actual patient data. The team can compare PK model performance using measurements of the model’s precision (root mean square error or RMSE) as well as its bias (mean percentage error, or MPE). When appropriate, these findings can be disseminated to the entire research network and the public at large — shaping healthcare policy in real-time.
The intricacies of evaluating PK models
For vancomycin dosing, many hospitals use a well-regarded PK model developed by Goti et al. in 2018, which was developed using data from 1,800 patients across two institutions. In 2020, several healthcare organizations participating in a democratized research network realized that the Goti model seemed to be overestimating exposure in elderly patients. After conducting a retrospective analysis using the data from nine hospitals, the centralized data science team found that an age adjustment for serum creatinine within the Goti model (which is also common to clinical practice) was responsible for the overestimation. The team developed a modified Goti model to correct the issue, which was used successfully by network members for nine months before it was published in early 2021 as the Tong model.
In 2021, the same data science team set out to determine which PK vancomycin model provides the lowest a priori RMSE in adults. Using a sample size of 37,000 patients, the team compared the performance of five models (Buelga 2005, Thomson 2009, Goti 2018, Colin 2019, and Tong 2021) in predicting a vancomycin course with at least one serum level for adult patients with a BMI of less than 40. The data scientists determined that the Tong model gave the most precise a priori predictions, while the Goti, Colin, and Thomson models all returned competitive results.
After these findings were shared with the research network, however, some participating hospitals reported that their patients’ predictions were actually worse using the Tong model than they were using the Thomson model. What could account for this deviation? While the data sciences team was unable to find a single factor associated with this variability, it nevertheless confirmed that the optimal model varies by institution. To determine which PK model will perform best for a particular hospital, researchers must analyze data specific to that hospital’s population.
Choosing the best default PK model for a specific hospital also depends partly on the hospital’s operational preferences. Some hospitals don’t want their clinicians to have to determine which model to use based on a patient’s clinical data. For example, many clinicians are unsure which PK model to use for the obese population. While PK models have been developed for patients with BMI >40 (obesity class III) and many general PK models include patients with a BMI of 30–40 (obesity class I–II) in their study dataset, it is difficult to find any information on model performance in this specific population. As a result, clinicians are left wondering: should these patients be managed using a PK model based on the general population, or a so-called obesity PK model, developed specifically for patients with a BMI >40 (obesity class III)?
To find out, the data sciences team tested the performance of five PK models (a modified version of Thomson 2009 with an eGFR cap of 150 ml/min, Adane 2015, Carreno 2017, Colin 2019, Tong 2021) on a mixed sample size of 6,744 patients with class I, II, and III obesity across 39 organizations. For patients with a BMI >40, the Carreno, Adane, and Tong PK models performed well, while the Colin model performed best for patients with a BMI of 30–40. However, the best performing single PK model across all obesity classes was the Tong model. Of course, based on the findings of earlier research, we would expect that hospitals might want to run this same analysis on their own site-specific datasets.
The impact of real-time analytics on model selection
Given that large-scale findings may not be fully applicable to the individual facility, how can hospitals determine which PK models to use? On their own, healthcare organizations do not have access to large enough data sets to determine a default model, and they also lack the resources necessary for site-specific model optimization.
The evolution of real-time analytics can solve time limitations, data science resources, and data access. When hospitals are members of a democratized research network, they can operate as their own research hub. A real-time analytics platform can give healthcare organizations greater agency over their precision dosing decisions, helping them research their patient populations to continually optimize dosing practices.
With aggregated, de-identified information on their patient demographics, clinical outcomes, and operational choices—like turnaround time between levels — hospitals can make informed decisions about their approach to precision medicine. Perhaps most excitingly, they can see their real-time results for a priori and a posteriori PK model performance and can filter results by age, weight, serum creatinine levels, and BMI, or even custom markers, such as disease state, ethnicity, co-administered medicines, and the like.
For example, a real-time analytics platform could allow a clinician who is searching for the best PK model for a male patient in his fifties with kidney failure and a BMI of 38 to select these criteria, filter the results, and calculate in real-time which PK model should work best. Then, once the patient’s levels return from the lab, the clinician can choose a different PK model to determine an optimal dosing regimen, depending on the data. Potentially, each hospital could set up a series of auto-selected, patient-specific PK model progressions that will return the optimal results, using a combination of validated large-scale data and site-specific data.

Jon Faldasz
As precision dosing technology evolves, healthcare organizations will be able to easily identify the best PK model fit for each patient in advance, improving outcomes on a case-by-case basis. A future in which hospitals act as independent research hubs will also serve the broader medical community at large. By investigating inconclusive, localized data signals using national data from thousands upon thousands of patients, research scientists can identify and disseminate new medical truths much more rapidly. The rise of democratized research networks will inform our collective understanding of how precision dosing works, changing how our clinicians practice medicine in the years to come.
Jon Faldasz, PharmD BCPS, is the senior director of product and customer experience at InsightRX, a healthcare technology company that helps clinicians individualize treatment at the point of care.
Filed Under: Data science, Infectious Disease



Tell Us What You Think!
You must be logged in to post a comment.